Deep Reinforcement Learning
- 실제 화면
- Deep Reinforcement Learning
- Code - {:.} Installing Dependencies - {:.} Replay Memory - {:.} Model - {:.} Training - {:.} DQN 학습시 중요 포인트 - {:.} Convert Video To GIF

실제 화면
아래는 실제로 DQN을 갖고서 돌린 실제 예제입니다.
실제 코드로 돌려보고 거의 1년후에나 블로그에 정리하네요.. ㅎㅎ;;
Deep Reinforcement Learning
- Deep Q Learning Nature Paper - Human-level control through deep reinforcement learning
- Playing Atari with Deep Reinforcement Learning
- LET’S MAKE A DQN: FULL DQN
Deep Q Network의 특징
Q-network에서 neural network를 사용하면 DQN은 다음과 같은 특징을 통해 향상을 시켰습니다.
- Multi-layer convolutional network를 통해서 더 복잡한 문제를 해결함
- Experience Replay를 통해 더 stable한 모델을 만들수 있게 됨
- target network 를 사용 (즉 2개의 neural network를 사용)
Future Discounted Return
Agent의 목표는 future reward를 최대치로 하는 actions을 선택하는 것입니다.
여기서 future reward란 \(\gamma\) 배수만큼 (a factor of \(\gamma\) per time-step) discounted 되는 것을 의미합니다.
쉽게 이야기해서 먼미래의 reward일수록, 더 적은 reward로 계산하겠다는 뜻입니다.
\(T\) 는 게임이 끝나는 시점의 time-step을 의미하며 \(\gamma \in [0, 1]\) 의 값을 갖습니다.
아래의 코드에서는 gamma 값이 시간의 흐름에 따른 변화를 그렸습니다.
먼 미래의 reward값일수록 0에 가까운 gamma값과 곱해야 하기 때문에
코앞의 reward는 가중치가 높고, 먼 미래는 reward는 가중치가 낮게 됩니다.
def gamma_values(gamma=0.9, n=50):
return [gamma**i for i in range(1, n)]
plot(gamma_values())
title('gamma value in regard with t. gamma=0.9, n=50')
xlabel('time t')
ylabel('gamma value')
grid()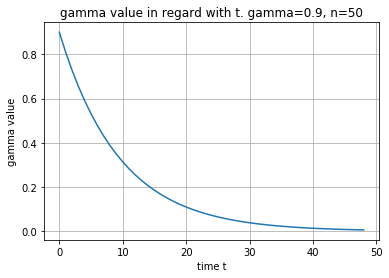
Optimal action-value Function and Bellman Equation
기본적으로 Reinforcement Learning의 목표는 expected return을 최대치로 하는 policy를 학습하는 것이며,
아래의 공식과 같은 Optimal action-value function \(Q^{*}(s, a)\) 을 사용합니다.
즉 어떤 특정 state \(s_t\) 에서 특정 action \(a_t\) 를 취했을때 얻게되는 expected return 을 나타냅니다.
Optimal Action-Value Function은 Bellman Equation을 따릅니다.
만약 optimal value \(Q^{*}(s^{\prime}, a^{\prime})\) (여기서 \(s^{\prime}\)는 next time-step의 state이고, \(a^{\prime}\)는 모든 가능한 actions들을 말함) 의 값을 알고 있다면,
expected value \(r + \gamma Q^{*}(s^{\prime}, a^{\prime})\)를 maximize 하는 action \(a^{\prime}\)을 선택하는 것에 기초를 두고 있습니다.
위의 bellman equation은 reinforcement learning에서 기본적인 방향틀이지 정말로 위의 공식을 사용해서 구한다는 뜻은 아닙니다.
실제 위의 공식을 “따라서” 구현한 알고리즘이 value iteration, policy iteration, Q-Learning, DQN 등등이 있습니다.
즉 일종의 개념이라고 생각하면 됩니다.
Nonlinear Approximator and Loss Function
일반적으로 iterative update를 통한 (value iteration 또는 policy iteration알고리즘등등) action-value function을 구하는 것은 일반화 시키지 못하며, 연산도가 매우 높아 복잡한 문제일수록 풀수가 없습니다. 따라서 function approximator를 사용하여 action-value function을 측정합니다.
\[Q(s, a; \theta) \approx Q^{*} (s, a)\]보통 Reinforcement Learning에서는 Linear function approximator를 사용하지만,
Deep Q Learning에서는 Nonlinear function approximator인 뉴럴네트워크를 사용합니다.
위의 공식에서 neural network function approximator로서 weights \(\theta\)가 Q-network로 사용되었습니다.
즉 Q-network는 parameters \(\theta\)를 조정해가면서 학습이 진행됩니다.
Loss function은 mean-squared error를 사용합니다.
이때 Bellman Equation의 optimal target values \(r + \gamma \max_{a^{\prime}} Q^{*}\left(s^{\prime}, a^{\prime}\right)\) 이 부분을
approximate target values \(y = r + \gamma \max_{a^{\prime}} Q \left( s^{\prime}, a^{\prime}; \theta^{(-)}_i \right)\) 으로 대체시켜줍니다.
따라서 최종 Loss Function은 다음과 같습니다.
\[L_i(\theta_i) = \mathbb{E}_{s, a, r} \left[ \left( r + \gamma \max_{a^{\prime}} Q\big( s^{\prime}, a^{\prime} ; \theta^{-}_i \big) - Q\big( s, a; \theta_{i} \big) \right)^2 \right]\]Target network \(Q^{-}\) 는 training중에만 사용되며 Loss를 구할때 사용이 됩니다.
즉 2개의 networks를 사용하는 것이며 target network는 주기적 또는 느리게 업데이트가 됩니다.
1개의 network사용시 예를들어… \(Q(s, a)\) 그리고 \(Q(s^{\prime}, a)\) 는 1step밖에 차이가 나지 않으며 이는 서로 매우 가까움을 의미합니다. 마치 고양이가 자기 자신의 꼬리를 잡으려고 계속 돌듯이.. target의 값이 지속적으로 shift되는 상황은 instability, oscillation 또는 divergence로 이어질수 있습니다.
Target network의 장점은 stable한 learning을 만들어주지만, 단점으로는 학습속도가 매우 저하되며
이유는 Q network에서 변경된 값은 바로 적용되지 않으며, target network 상당한 시간 이후에 업데이트가 되기 때문 입니다.
target network가 업데이트 되는 시점은 보통 10000번 정도의 step이후에 업데이가 되게 됩니다.
복잡한 문제일수록 target network의 update시점을 늦게 잡습니다. (예를 들어 50000)
문제가 복잡하지 않다면 update시점을 좀 빠르게 잡아도 됩니다.
구글 딥마인드에서 내놓은 DQN Nature 논문에서는 target network를 바로 이전 step의 network로 지칭하고 있습니다.
추후 딥마인드팀에서는 이 방법이 문제가 있다는것을 알았고, 추가적인 논문에서 target network의 update를 늦은 시점에서 하는 것을 발표합니다.
Frame-skipping Technique
간단히 말해 Agent는 모든 frame마다 action을 선택하는 것이 아니라, \(k\) 번째마다 action을 선택하는 형태입니다.
그리고 마지막에 했었던 action을 skipped frames에서 선택을 합니다.
이것을 통해서 많은 computation을 줄일수 있습니다.
구글 딥마인드 Nature논문에서는 \(k=4\) 값으로 실행했습니다.
Error Clipping
Mean Squared Error (MSE) loss function을 위해서 사용하였습니다.
\[\text{MSE} = \frac{1}{N} \sum^n_{i=1} \left( \hat{y}_i - y_i \right)^2\]문제는 제곱을 하게 되는 부분에서 MSE는 너무나 큰 값의 loss를 만들어내게 됩니다.
이는 DQN에서는 unstable한 learning이 될 수 있습니다.
따라서 다른 대안으로 Mean Absolute Error(MAE) 를 사용할 수 있습니다.
MSE가 값이 커질때 너무 커지는 단점이 있었다면, MAE의 경우 loss값이 작을때 너무 작아져서 학습이 느려지는 단점이 있습니다.
MSE와 MAE의 2가지의 단점을 극복한 loss function 이 있습니다.
Huber loss function을 사용하면 MSE와 MAE의 장점을 섞어서 사용할수 있습니다.
즉 loss값이 작을때는 MSE를 사용한것과 같으며, loss값이 크면 MAE를 사용한것과 같은 효과를 낼 수 있습니다.
여기서 \(L_\delta(a)\) 는 다음과 같습니다.
\[L_\delta(a)=\begin{cases} \frac{1}{2}a^2 & |a|\leq \delta,\\ \delta(|a|-\frac{1}{2}\delta) &\text{otherwise} \end{cases}\]delta \(\delta\) 는 값이 커지면 커질수록 y값의 증가량이 점점 커짐.
실제 딥마인드팀의 DQN 논문에서는 error clipping을 1과 -1사이로 제한을 하였습니다.
이렇게 제한을 걸면 여러게임에서 동일한 learning rate를 사용할수 있도록 만들어 줍니다.
즉 delta값이 제한됨으로서 다양한 게임에서 완만하게 학습될 수 있도록 해줍니다.
DELTA = 4
data = {'mean sqaured error': [],
'mean absolute error': [],
'huber': [],
'pseudo huber': [],
'my huber': []}
x = np.arange(-4, 4.1, 0.1)
def anderson_huber(delta, value):
"""
scipy.special.huber의 결과값과 동일하게 나옴.
"""
if abs(value) <= delta:
return 1/2 * value**2
return delta * (abs(value) - 1/2 * delta)
for y in x:
mse = mean_squared_error([0], [y])
mae = mean_absolute_error([0], [y])
he = huber(DELTA, 0-y)
my_he = anderson_huber(DELTA, 0-y)
phe = pseudo_huber(DELTA, 0-y)
data['mean sqaured error'].append(mse)
data['mean absolute error'].append(mae)
data['huber'].append(he)
data['pseudo huber'].append(phe)
data['my huber'].append(my_he)
del data['pseudo huber']
data = pd.DataFrame(data, index=x)
data.plot()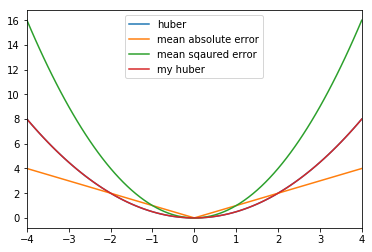
Experience Replay and Loss Function
게임을 진행하면서 학습을 할 경우 observation sequence같의 연관성(correlation)때문에 학습이 제대로 안 될수 있습니다.
연관성을 끊어주는 방법으로 experience replay를 사용합니다.
먼저 Agent의 experiences \(e_t = (s_t, a_t, r_t, s_{t+1} )\)를 각각의 time-step마다 data set \(D_t = \{ e_1, e_2, ..., e_t \}\)에 저장합니다.
학습시 Q-Learning updates를 uniformly random으로 꺼내진 experiences \((s, a, r, s^{\prime}) \sim U(D)\) 통해 실행하게 됩니다.
궁극적으로 Loss function 은 다음과 같게 됩니다.
Deep Q-Learning with Experience Replay Algorithm

Code
전체코드는 아래의 링크에서 확인 할수 있습니다.
https://github.com/AndersonJo/dqn-pytorch
Installing Dependencies
Pygame을 설치합니다.
sudo pip3 install pygamePygame Environment를 설치합니다.
git clone https://github.com/ntasfi/PyGame-Learning-Environment.git
cd PyGame-Learning-Environment/
sudo pip3 install -e .Pygame을 Gym에서 실행시켜줄수 있는 gym-ple를 설치합니다.
git clone https://github.com/lusob/gym-ple.git
cd gym-ple/
sudo pip3 install -e .Replay Memory
class ReplayMemory(object):
def __init__(self, capacity=REPLAY_MEMORY):
self.capacity = capacity
self.memory = deque(maxlen=self.capacity)
self.Transition = namedtuple('Transition', ('state', 'action', 'reward', 'next_state'))
self._available = False
def put(self, state: np.array, action: torch.LongTensor, reward: np.array, next_state: np.array):
"""
저장시 모두 Torch Tensor로 변경해준다음에 저장을 합니다.
action은 select_action()함수에서부터 LongTensor로 리턴해주기 때문에,
여기서 변경해줄필요는 없음
"""
state = torch.FloatTensor(state)
reward = torch.FloatTensor([reward])
if next_state is not None:
next_state = torch.FloatTensor(next_state)
transition = self.Transition(state=state, action=action, reward=reward, next_state=next_state)
self.memory.append(transition)
def sample(self, batch_size):
transitions = sample(self.memory, batch_size)
return self.Transition(*(zip(*transitions)))Model
딥마인드팀에서 사용한 DQN 모델입니다.
| Layer | Input | Filter Size | Stride | Filter 갯수 | Activation | Output |
|---|---|---|---|---|---|---|
| conv1 | 84 x 84 x 4 | 8 x 8 | 4 | 32 | ReLU | 20 x 20 x 32 |
| conv2 | 20 x 20 x 32 | 4 x 4 | 2 | 64 | ReLU | 9 * 9 * 64 |
| conv2 | 9 x 9 x 64 | 3 x 3 | 1 | 64 | ReLU | 7 x 7 x 64 |
| fc1 | 7 x 7 x 64 | 512 | ReLU | 512 | ||
| fc2 | 512 | 2 | Linear | 2 |
class DQN(nn.Module):
def __init__(self, n_action):
super(DQN, self).__init__()
self.n_action = n_action
self.conv1 = nn.Conv2d(4, 32, kernel_size=8, stride=4, padding=0) # (In Channel, Out Channel, ...)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=0)
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0)
self.affine1 = nn.Linear(3136, 512)
self.affine2 = nn.Linear(512, self.n_action)
def forward(self, x):
h = F.relu(self.conv1(x))
h = F.relu(self.conv2(h))
h = F.relu(self.conv3(h))
h = F.relu(self.affine1(h.view(h.size(0), -1)))
h = self.affine2(h)
return hTraining
def train(self, gamma: float = 0.99, mode: str = 'rgb_array'):
while True:
states = self.get_initial_states()
losses = []
checkpoint_flag = False
target_update_flag = False
play_steps = 0
reward = 0
done = False
while True:
# Get Action
action: torch.LongTensor = self.select_action(states)
for _ in range(self.frame_skipping):
# step 에서 나온 observation은 버림
observation, reward, done, info = self.env.step(action[0, 0])
next_state = self.env.get_screen()
self.add_state(next_state)
if done:
break
# Store the infomation in Replay Memory
next_states = self.recent_states()
if done:
self.replay.put(states, action, reward, None)
else:
self.replay.put(states, action, reward, next_states)
# Change States
states = next_states
# Optimize
if self.replay.is_available():
loss, reward_sum, q_mean, target_mean = self.optimize(gamma)
losses.append(loss[0])
if done:
break
# Increase step
self.step += 1
play_steps += 1
# Target Update
if self.step % TARGET_UPDATE_INTERVAL == 0:
self._target_update()
target_update_flag = True
def optimize(self, gamma: float):
# Get Sample
transitions = self.replay.sample(BATCH_SIZE)
# Mask
non_final_mask = torch.ByteTensor(list(map(lambda ns: ns is not None, transitions.next_state))).cuda()
final_mask = 1 - non_final_mask
state_batch: Variable = Variable(torch.cat(transitions.state).cuda())
action_batch: Variable = Variable(torch.cat(transitions.action).cuda())
reward_batch: Variable = Variable(torch.cat(transitions.reward).cuda())
non_final_next_state_batch = Variable(torch.cat([ns for ns in transitions.next_state if ns is not None]).cuda())
non_final_next_state_batch.volatile = True
# Reshape States and Next States
state_batch = state_batch.view([BATCH_SIZE, self.action_repeat, self.env.width, self.env.height])
non_final_next_state_batch = non_final_next_state_batch.view(
[-1, self.action_repeat, self.env.width, self.env.height])
non_final_next_state_batch.volatile = True
# Clipping Reward between -2 and 2
reward_batch.data.clamp_(-1, 1)
# Predict by DQN Model
q_pred = self.dqn(state_batch)
q_values = q_pred.gather(1, action_batch)
# Predict by Target Model
target_values = Variable(torch.zeros(BATCH_SIZE, 1).cuda())
target_pred = self.target(non_final_next_state_batch)
target_values[non_final_mask] = reward_batch[non_final_mask] + target_pred.max(1)[0] * gamma
target_values[final_mask] = reward_batch[final_mask]
loss = F.smooth_l1_loss(q_values, target_values)
# loss = torch.mean((target_values - q_values) ** 2)
self.optimizer.zero_grad()
loss.backward()
if self.clip:
for param in self.dqn.parameters():
param.grad.data.clamp_(-1, 1)
self.optimizer.step()
reward_score = int(torch.sum(reward_batch).data.cpu().numpy()[0])
q_mean = torch.sum(q_pred, 0).data.cpu().numpy()[0]
target_mean = torch.sum(target_pred, 0).data.cpu().numpy()[0]
return loss.data.cpu().numpy(), reward_score, q_mean, target_meanDQN 학습시 중요 포인트
모델을 만드는 중 알아낸 사실들
1. Pooling Layer 사용하지 말것
object recognition같은 부분에서는 pooling layer가 효율적이지만,
DQN처럼 새의 위치, 파이프의 위치, 공의 위치, 벽돌의 위치, 주인공의 위치 등등 이러한 위치정보가 중요한 경우 pooling layer사용시 translation invariance 를 일으켜서
위치정보 자체가 없어지게 됩니다. 실제 pooling layer를 설정하고 학습시.. 학습을 하면서 에러률이 떨어지는게 아니라 갑작스럽게 큰 loss값이 나오게 됩니다.
0.013, 0.024 뭐 이런식으로 나오다가 갑작이 60 이렇게 나옵니다. 계속 학습시 loss값은 점점 더 높아지면서 500~600처럼 말도안되게 큰 값이 계속 나옵니다.
2. Dropout 효율성 없음
CNN에서 Dropout자체가 효율성이 없음.
3. Batch Normalization 은 ReLU다음에 사용
이게 좋다고 함
4. prediction값이 이상함
예측값이 이상하게 모든 상황에서 값이 거의 동일하게 나온다면 Target Network update주기가 너무 느려서 그런 경우가 있음.
이 경우 target network의 update 주기를 좀 더 빠르게 해 주면 됨
5. loss 값을 주시할것
Loss값이 안정적으로 큰 틀 안에서 떨어지는 것이 중요함.
DQN의 특성상.. 로그로 올라오는 loss값을 보면 oscillation이 약간 존재하나.. (예를 들어 0.0013 -> 0.021 -> 0.0056 처럼 왔다리 갔다리 함)
몇십분동안 큰 loss의 트렌드는 떨어지는 것을 확인 할수 있다. 이런 트렌드를 그리지 않으면.. 모델에 문제가 있는 경우.
Convert Video To GIF
기록된 게임 플레이 동영상은 GIF로 변경할수 있습니다.
mkdir frames
ffmpeg -i video.mp4 -qscale:v 2 -r 25 'frames/frame-%03d.jpg'
cd frames
convert -delay 4 -loop 0 *.jpg myimage.gif